
I den daglige undervisning og i større opgaver som SRP, SRO, SOP og SSO, er det af og til en fordel at kunne generere nye data, der ser realistiske ud og følger forventede mønstre.
Det er sprogmodeller i mange chatbots (GPT5.2, Gemini3), blevet meget bedre til. Eller også er jeg blevet bedre til at prompte? Som altid, vil en mere konkret og specifik prompt give et bedre og mere brugbart resultat.
Her nedenfor et forsøg på at generere syntetiske data for biogas-produktion i et produktions-anlæg. Der er 200 forsøg (10 første er vist) med forskellig biomasse, som giver forskelligt udbytte:
| protein | kulhydrat | cellulose | fedtstof | C_N | pH | biogas_pct_max | |
|---|---|---|---|---|---|---|---|
| 0 | 0.131 | 0.239 | 0.048 | 0.030 | 29.638 | 7.044 | 83.132 |
| 1 | 0.214 | 0.104 | 0.028 | 0.082 | 29.905 | 7.170 | 71.910 |
| 2 | 0.202 | 0.136 | 0.028 | 0.062 | 31.459 | 7.268 | 68.486 |
| 3 | 0.127 | 0.209 | 0.032 | 0.064 | 31.824 | 7.062 | 83.986 |
| 4 | 0.093 | 0.254 | 0.044 | 0.052 | 32.473 | 7.081 | 82.486 |
| 5 | 0.118 | 0.148 | 0.056 | 0.133 | 30.070 | 7.251 | 60.701 |
| 6 | 0.106 | 0.206 | 0.046 | 0.088 | 29.741 | 7.273 | 63.081 |
| 7 | 0.187 | 0.195 | 0.062 | 0.018 | 29.627 | 6.998 | 84.139 |
| 8 | 0.187 | 0.111 | 0.045 | 0.102 | 29.809 | 7.008 | 76.834 |
| 9 | 0.218 | 0.151 | 0.077 | 0.031 | 30.474 | 6.997 | 78.778 |
Proceduren kan være som følger:
- Angiv formålet med datasættet, samt hvilke data, der skal være i sættet.
- Angiv sammenhænge mellem data. Hvis sammenhængene fremgår af en kilde, som sprogmodellen selv kan tilgå, kan modellen forsøge at udlede sammenhængene.
- Få sprogmodellen til at afbilde datasættet, så du kan få et overblik over om de forventede sammenhænge er tilstede, og om de er for kraftige eller svage (se billede herunder).
- Få sprogmodellen til at lægge datasættet i en fil fx csv-fil, og angiv krav til kolonne- og decimal-adskillelse.
- Hvis data skal bruges til en specifik matematisk undersøgelse (fx regression eller maskinlæring), så lad sprogmodellen teste denne. Opstil evt. krav til korrelation, nøjagtighed o.l.
Nedenfor afbildning af de 200 syntetiske data fra ovenfor. Kig særligt på nederste linje af plots, hvor produktionen gerne skulle følge pH og C/N. Plottet mellem C/N og protein viser, at desto mere protein, jo lavere bliver C/N forholdet (mere N). Lavere C/N forhold giver lavere pH (pga ammonium-dannelse). Der er også plots, som giver mindre mening fx mellem kulhydrat og protein.
Det kan blive elevernes opgave at forklare nogle af sammenhængene.
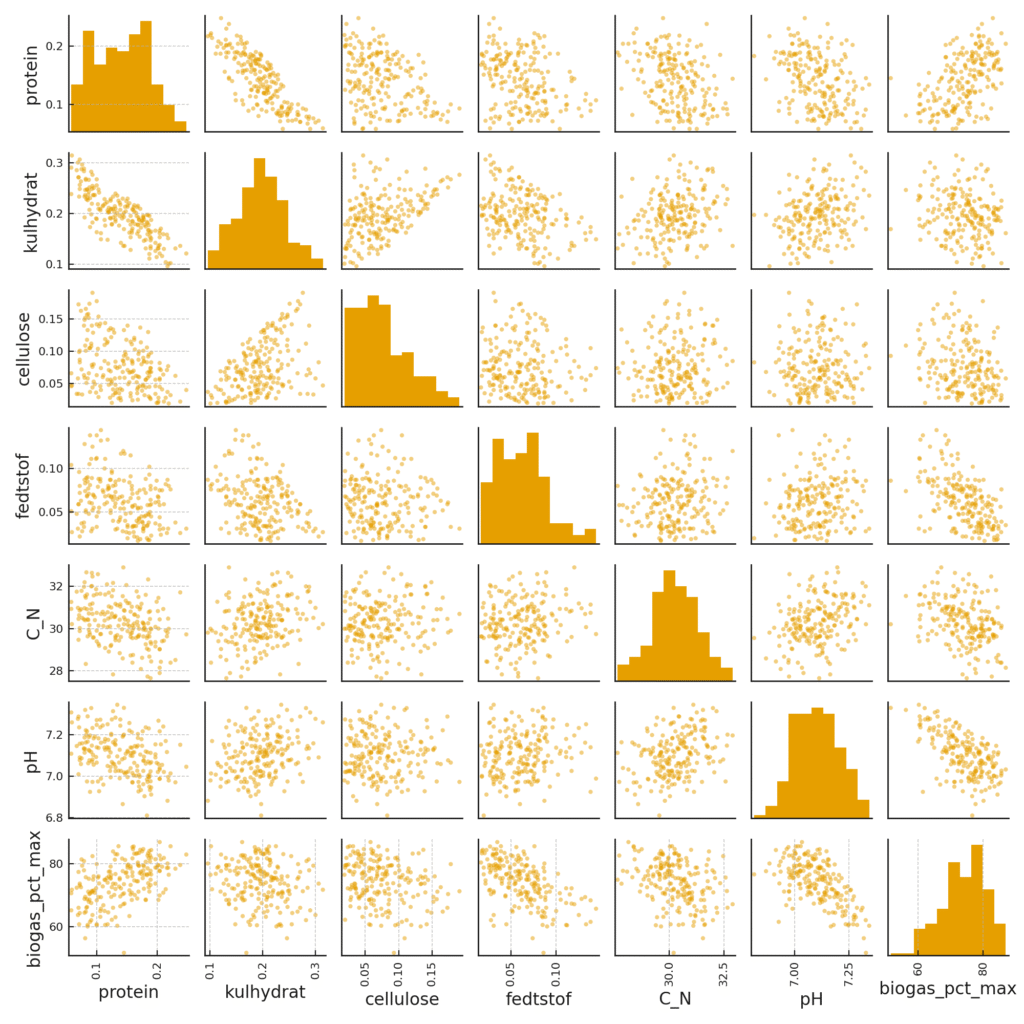
Det kan tage flere minutter, at få et respons fra sprogmodellen. Det er altid lidt random, hvad der kommer som output. Nogle gange kan plots ikke vises. Andre gange vises alle 200 linjer af data osv. Det kan kræve en del iterationer, hvis man ønsker helt bestemte udtryk eller nøjagtighed. Man kan også tilføje krav til spredning og intervaller for data, men dem kender man ikke altid præcist, så her er det måske bedre at lade modellen give et bud.
Man bør deklarere, at der er tale om syntetiske data. Om ikke andet for at undgå at tiltroen til videnskaben og viden generelt ikke forsvinder helt.